CURL: Contrastive Unsupervised Representations for Reinforcement Learning¶
Tldr
- Improves the sample efficiency when learning from pixels by using contrastive learning, a self-supervised method, as an auxiliary task.
- The contrastive objective works in a similar way as in SimCLR, using random cropping as an augmentation method.
- After 100k interactions, outperforms all other methods on DM Control Suite, and shows strong results on Atari.
Learning from pixels¶
In reinforcement learning, solving a task from pixels is much harder than solving an equivalent task using "physical" features such as coordinates and angles. This makes sense: you can consider an image as a high-dimensional vector containing hundreds of features, which don't have any clear connection with the goal of the environment!
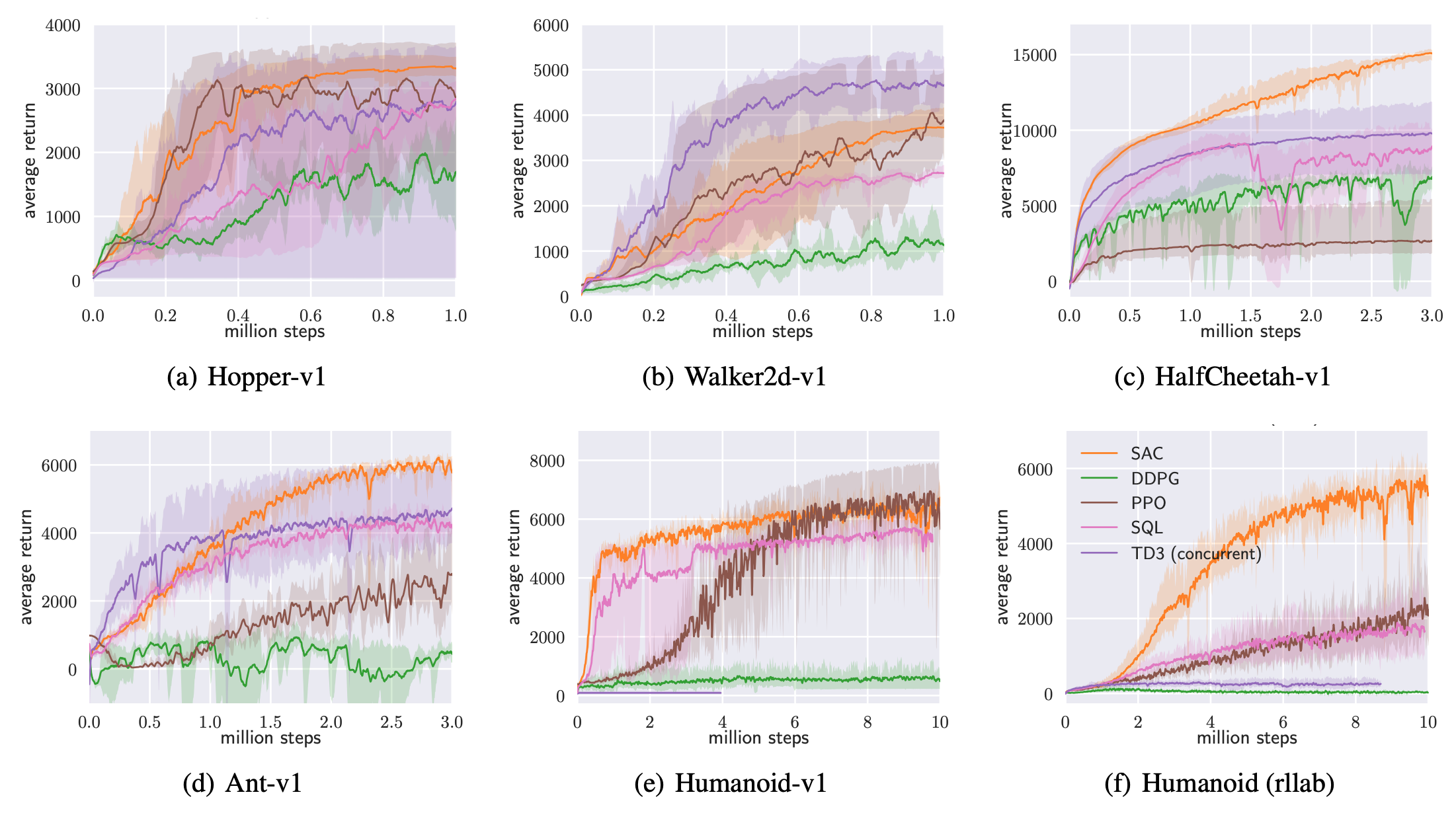
As a result, you generally need a lot more interactions between an agent and its environment in order to learn a good policy from pixels. For example, the figure below shows the results of multiple recent RL methods on the DeepMind Control Suite, learning from physical features. Take a look at the x-axis: depending on the complexity of the task, the agents are trained from 1 to 10 million interactions: 1
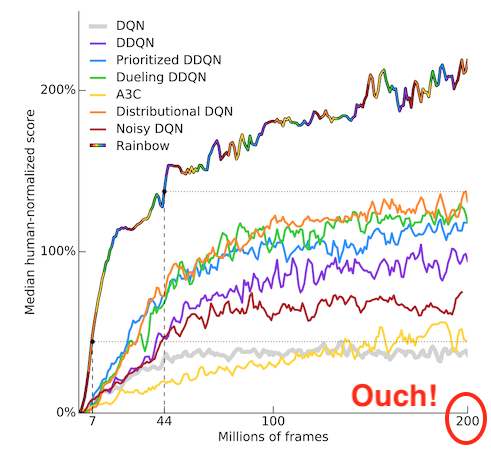
On the other hand, let's have a look at results using Atari games as a benchmark. There is no notion of "physical" features with the Atari emulator: the only observations the agent can work with are RGB images. The agents now have to be trained for a staggering 200 million frames!2 Some distributed approaches even consider numbers up to a billion.
This low sample-efficiency is clearly a problem. Not only does it mean the experiment turn-around time is excessive, it also means that there can be little hope of bringing such methods to the real world. Can you imagine having to collect a billion real-world interactions?
The paper we are considering takes a stab at this problem by bringing recent advances from vision and NLP to reinforcement learning. Contrastive learning takes advantage of data augmentation to learn more efficiently. CURL shows that it can be very useful in the context of RL to learn a good latent representation faster.
What is contrastive learning?¶
The core idea is to compare (contrast!) pairs of augmented samples. We consider two kinds of such pairs:
- Positive pairs consist of two different augmentations of the same sample
- Negative pairs contain augmentations of two different samples
For each original sample, we create both positive and negative pairs. The contrastive representation is then learned by maximizing the agreement between positive pairs, and minimizing the agreement between negative pairs.
Contrastive learning has seen dramatic progress in recent years for language and vision. See for example BERT, an application to masked language modeling3, or the SimCLR framework, used to learn visual representations4.
The way contrastive learning is implemented in CURL is mostly influenced by the SimCLR framework4, Momentum Contrast (MoCo)5 and Contrastive Predictive Coding (CPC)6.
How CURL works¶
With CURL, the same latent representation is used for both the RL algorithm and the contrastive learning, as illustrated below: 7
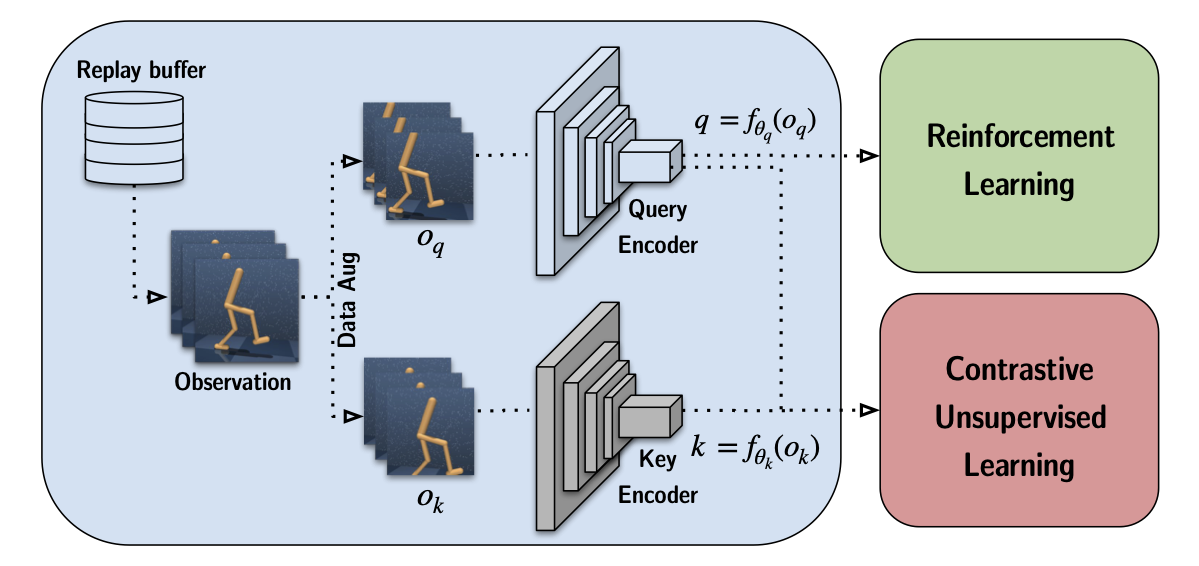
CURL uses random crops to augment the observations. Since most RL methods use frame-stacking, each observation is effectively a "stack" of sequential images. CURL preserves their temporal structure by applying the same augmentation to each frame in the stack.
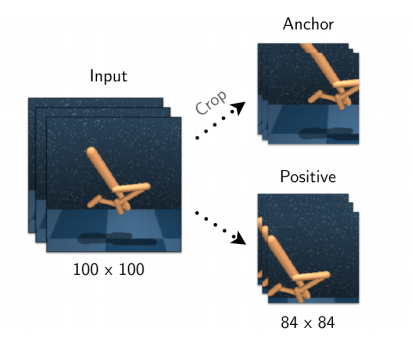
The illustration below gives an example of a positive pair: the same observation is augmented in two different ways. The representation will be changed in a way that maximizes their agreement. 7
Evaluation¶
Using a contrastive objective as an auxiliary task appears to significantly improve the performance of the RL algorithm. CURL's performance is evaluated in two settings:
- with SAC on DeepMind Control Suite (continuous control)
- with data-efficient Rainbow DQN on Atari games (discrete control).
In both cases, the performance is evaluated after 100k interactions, as the goal is to evaluate sample efficiency rather than asymptotic performance.
Results are remarkable on DeepMind Control Suite : 7  (The last column, State SAC, uses physical states and is used as an "oracle" upper-bound.)
(The last column, State SAC, uses physical states and is used as an "oracle" upper-bound.)
Results are very good on Atari games. This is again after 100k interactions: 7 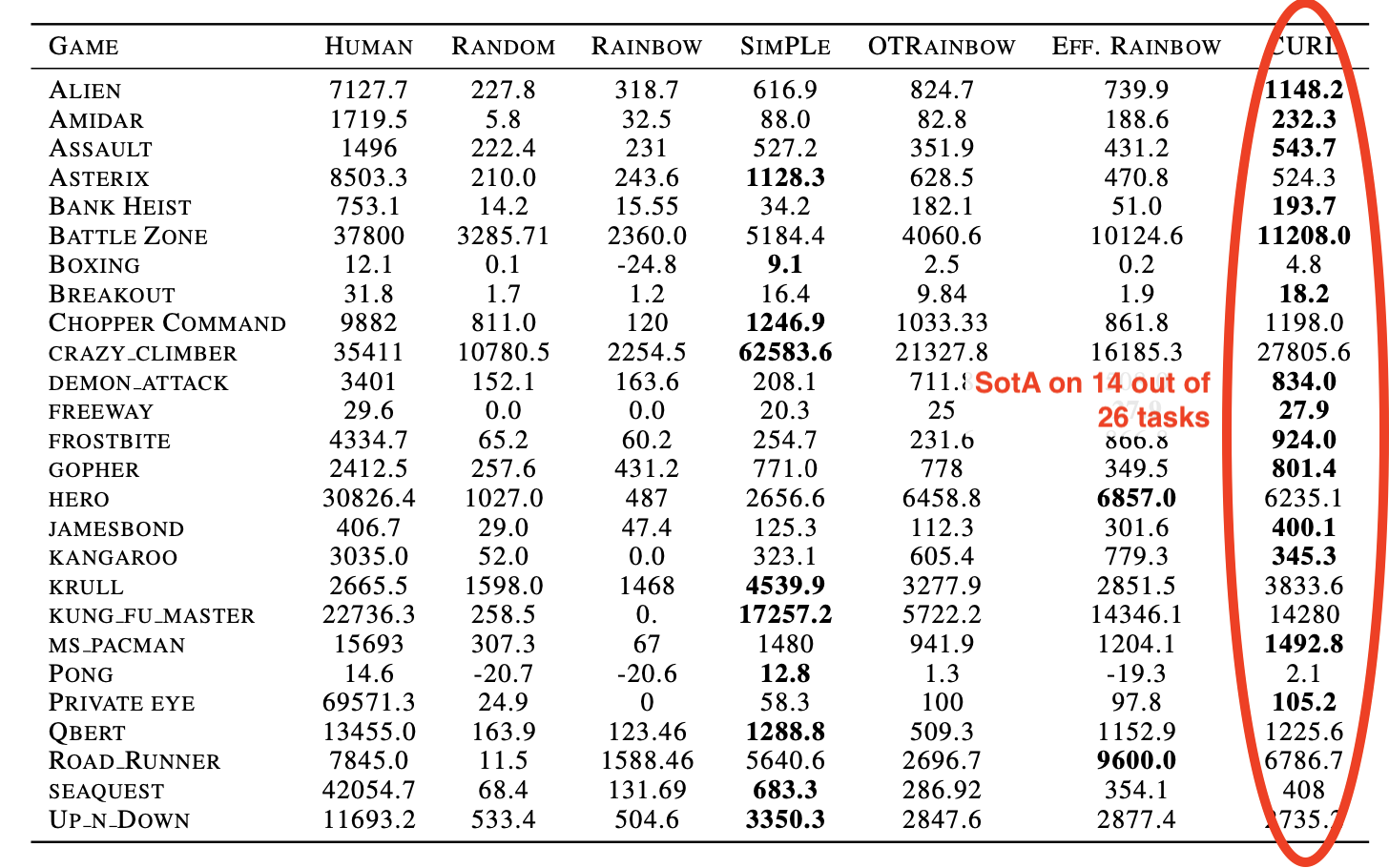
How can this difference in performance be explained? One idea explored in the appendix is that in some environments, there is simply not enough information to fully recover the state when looking only at the pixel data: the problem then becomes partially observable and therefore much harder.
Key concepts¶
"Building blocks" involved in this work:
- Focuses on sample efficiency
- Uses contrastive learning
- Uses auxiliary tasks
- Benchmarked on DeepMind Control Suite
- Benchmarked on Atari games
Limitations¶
 No comparison with
No comparison with Links¶
- Official code repository, a PyTorch implementation for SAC on DeepMind Control Suite
- Official project page, which provides a short summary of the paper
- Twitter summary from first author
Authors¶
- Aravind Srinivas Twitter/Scholar/Academic
- Michael Laskin Twitter/Scholar/Academic
- Pieter Abbeel Twitter/Scholar/Academic
-
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor ↩
-
Rainbow: Combining Improvements in Deep Reinforcement Learning ↩
-
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding ↩
-
A Simple Framework for Contrastive Learning of Visual Representations (SimCLR) ↩↩
-
Momentum Contrast for Unsupervised Visual Representation Learning (MoCo) ↩
-
Data-Efficient Image Recognition with Contrastive Predictive Coding (CPC) ↩