Asynchronous Methods for Deep Reinforcement Learning¶
Tldr
- Introduces an RL framework that uses multiple CPU cores to speed up training on a single machine.
- The main result is A3C, a parallel actor-critic method that uses shared layers between actor and critic, n-step returns and entropy regularization.
- A synchronous version called A2C, optimized for GPUs, is generally preferred nowadays.1
February 2016 - arXiv
Scaling up RL¶
This paper introduces a multi-threaded training framework. Its main result is the A3C algorithm. When this paper came out, it beat the state of the art on Atari games while training for only half the time! The core idea is to scale up training by using the multiple CPU cores.
Scaling up training brings two advantages:
- Shorter training times: we can throw more compute at the problem
- More stable training: it decorrelates the experiences observed by the agent
Decorrelating experiences¶
A common problem in reinforcement learning is the correlation between successive experiences. When using off-policy methods such as DQN, it is possible to use a replay buffer to store previous experiences that can then be sampled randomly. This is more complicated when using on-policy algorithms such as policy gradient methods, as they can't reuse past experiences.
The proposed framework solves this problem by executing multiple agents in parallel:
Instead of experience replay, we asynchronously execute multiple agents in parallel, on multiple instances of the environment. This parallelism decorrelates the agents’ data into a more stationary process, since at any given timestep the parallel agents will be experiencing a variety of different states.
For off-policy methods, this is a memory vs compute trade-off:
- Replay buffers are memory-intensive, but use little computing power
- Parallel agents are CPU-intensive, but are not as memory-hungry as replay buffers
Note that it would be possible to combine a replay buffer - either central or separate per worker - with parallel agents. Going in this direction leads us to architectures such as Gorila or Ape-X.
For on-policy methods, there is no downside to using parallel agents, as these methods can't learn from previous experiences! (Following this publication other algorithms came up to address this limitation such as ACER, IMPALA and others.)
Implementation details¶
One of the goals of this framework is to take advantage of multi-cores CPUs without relying on GPUs:
Our parallel reinforcement learning paradigm also offers practical benefits. Whereas previous approaches to deep reinforcement learning rely heavily on specialized hardware such as GPUs or massively distributed architectures, our experiments run on a single machine with a standard multi-core CPU.
Since the gradients are calculated on the CPU, there's no need to batch large amount of data to optimize performance, as would be the case with a GPU. As a result, the updates are performed asynchronously: each agent performs a number of training steps, then updates the global parameters without having to care about the status of the other agents.
Here's the algorithm as pseudocode: 2

Evaluation¶
The training framework proposed in this paper could be used with any RL methods. In order to find which method works best, they try it out with SARSA, deep Q-learning, n-step deep Q-learning, and advantage actor-critic.
This evaluation is performed on four different platforms:
- The traditional Atari learning environment, using 5 games
- The Torcs driving simulator, using 4 game modes
- The Mujoco domain, using 14 tasks
- A custom "labyrinth" environment (released afterward as DeepMind Lab)
Using the parallel framework almost always increases training speed. The results are especially impressive when combining it with the advantage actor-critic method. See for example the last line of these benchmarks on 3 Atari games: 2
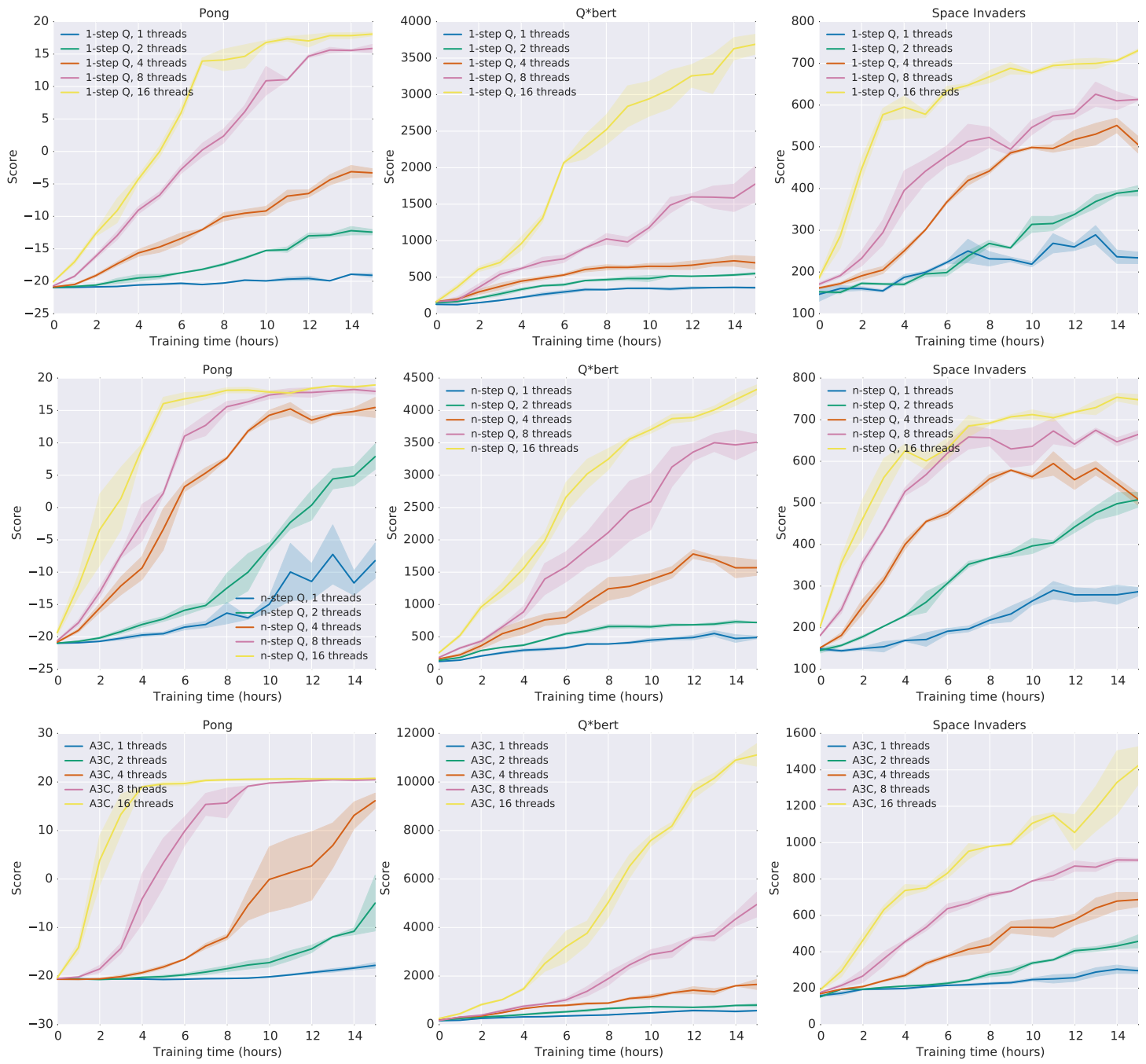
This method is called A3C, for "Asynchronous Advantage Actor Critic" - this paper's claim to fame!
The paper then provide an evaluation of A3C on 57 Atari games compared to the other top RL methods of the time. Looking at mean performances, A3C beats the state of the art while training twice faster than its competition: 2
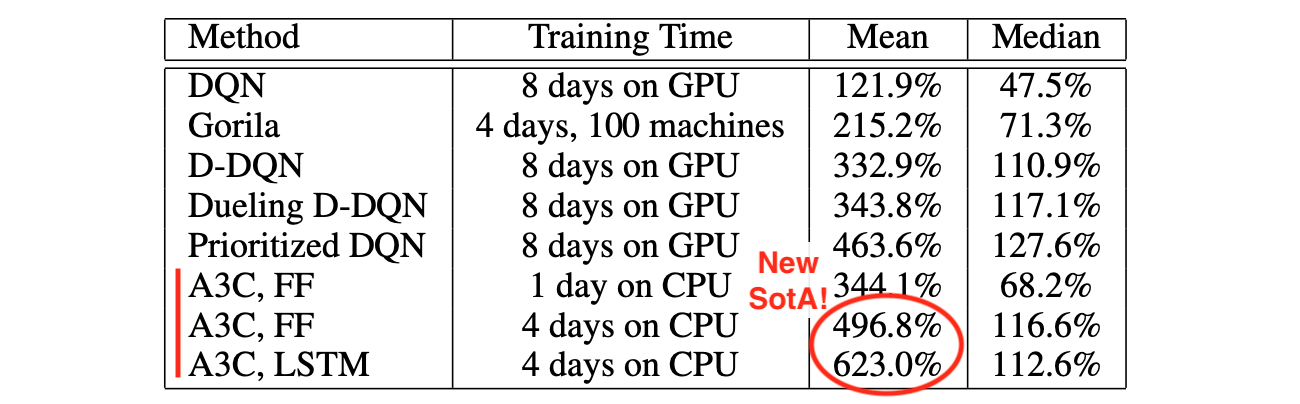
It should be noted that the question of evaluation of RL agents, and more specifically evaluation when using Atari games, has been hotly debated since this paper came out. The use of mean performance for example is no longer regarded as reliable as some games can easily skew the final ranking.
Extra improvements¶
Beyond its parallel nature, A3C includes a number of other improvements compared to vanilla advantage actor critic:
- The layers are shared between the actor and the critic
- Both actor and critic use n-step learning
- The policy uses entropy regularization
- Adding an LSTM layer helps in some environments
- The RMSProp optimizer uses shared statistics between agents
From A3C to A2C¶
A3C was explicitly designed to take advantage of CPUs with many cores, and to not require a GPU. With this use case in mind, asynchronous updates made a lot of sense: they don't require any synchronisation between the agents, and parameter updates can be done Hogwild syle without locking.
But GPUs are much more efficient then CPUs when optimizing large policies. When the policy becomes large enough, it starts making more sense to sacrifice asynchronous updates in order to feed large batches to a GPU. In that case, the agents don't compute the gradients themselves anymore. Instead, they perform a rollout and send the experiences to the master thread, which performs gradient updates in a synchronous way.
This non-asynchronous version is simply called A2C (Advantage Actor Critic) 1. It generally performs comparably to A3C in terms of final performance, but it trains even faster as it can take advantage of a GPU. The paper Accelerated Methods for Deep Reinforcement Learning provides advanced analysis between the two as well as optimization insights.
In hindsight¶
 Executing multiple agents in parallel is a good way to decorrelate observations
Executing multiple agents in parallel is a good way to decorrelate observations Asynchronous updates are not a good match for GPU training: see A2C
Asynchronous updates are not a good match for GPU training: see A2C- Using exclusively on-policy data is bad for sample efficiency: see ACER, IMPALA
Key concepts¶
"Building blocks" involved in this work:
- Builds on Actor-Critic methods
- Introduces a multi-threaded parallel training method
- Uses entropy regularization
- Uses an LSTM Recurrent Neural Network layer
- Uses multi-step return
- Uses shared layers between policy and value functions
- Benchmarked on Atari games
Links¶
- Actor-Critic Methods: A3C and A2C from Daniel Seita, a detailed walkthrough
Authors¶
- Volodymyr Mnih Twitter/Scholar/Academic
- Adrià Puigdomènech Badia Scholar
- Mehdi Mirza Twitter/Scholar/Personal
- Alex Graves Scholar/Academic
- Tim Harley Twitter/Scholar
- Timothy P. Lillicrap Twitter/Scholar/Personal
- David Silver Scholar/Personal
- Koray Kavukcuoglu Twitter/Scholar/Personal